
データの正規化は、データベースにおける重要なプロセスであり、情報を整理し、冗長性を減少させるための手法です。このプロセスは、データの整合性を保ちながら、効率的にデータを管理することを目的としています。正規化を行うことで、データの重複や矛盾を避けることができ、より信頼性の高いデータベースを構築することが可能になります。
データの正規化は、特に大規模なデータベースや複雑なデータ構造において、その効果が顕著に現れます。例えば、顧客情報や製品情報などが含まれるデータベースでは、正規化によって必要な情報を簡単に取得できるようになります。
このように、データの正規化は、単なる技術的な手法ではなく、ビジネスや研究においても非常に重要な役割を果たします。特に、ビッグデータ時代においては、正規化されたデータが分析や意思決定の基盤となります。
-
QITにおける「データの正規化」の意味は?
-
A
データの正規化とは、冗長性を排除し、一貫性のある形でデータを整理するプロセスです。
データの正規化が必要な理由
データの正規化は、単なる効率性向上だけでなく、多くの利点があります。特にビジネスや研究においては、正確で一貫したデータが求められるため、その重要性は増しています。
冗長性の排除
まず第一に、正規化によって冗長性が排除されます。これは同じ情報が複数回記録されることを防ぎます。例えば、顧客情報が異なるテーブルで何度も保存されていると、その情報を更新する際に全てのテーブルで変更しなければならず、手間がかかります。
正規化を行うことで、顧客情報は一つのテーブルに集約され、そのテーブルへの変更だけで済むようになります。これによって、データ管理が簡素化されます。
整合性と一貫性の向上
次に、整合性と一貫性が向上します。冗長なデータがあると、一部だけを更新した場合などに矛盾が生じる可能性があります。しかし、正規化されたデータベースでは、一つの場所でのみ情報が管理されるため、このようなリスクが減少します。
例えば、顧客の住所変更があった場合、その情報を一つのテーブルで更新するだけで済むため、一貫した情報を保つことができます。

データの正規化プロセスとその段階
データの正規化は段階的なプロセスであり、それぞれ異なる目的があります。一般的には以下のような「正規形」と呼ばれる段階があります。
第一正規形(1NF)
第一正規形は基本的なステップであり、この段階では各フィールドには原子値(単一値)が含まれ、一意な識別子(主キー)が設定されている必要があります。これによって重複した行や複数値を持つフィールドを排除します。
例えば、「顧客名」と「購入商品」というフィールドがある場合、一つの商品だけではなく複数の商品名を同じフィールド内に入れてしまうと1NF違反となります。この場合、それぞれの商品名は別々の行として記録する必要があります。
第二正規形(2NF)
第二正規形では、すべての非キー属性が主キーに完全に依存していることが求められます。つまり、一部の属性だけが主キーによって決定される場合、それらを別テーブルに分ける必要があります。
例えば、「注文ID」と「商品名」、「顧客名」がある場合、「商品名」が「注文ID」にのみ依存している場合は、「商品名」を別テーブルとして分ける必要があります。
- 第一正規形(1NF):原子値のみを持つフィールド。
- 第二正規形(2NF):非キー属性は主キーに完全依存。
- 第三正規形(3NF):非キー属性間で依存関係を持たない。
- ボイス・コッド正規形(BCNF):より厳密な依存関係制約。
- 第四・第五正規形:さらに高度な冗長性排除。
これらの段階を経ていくことで、より効率的で整然としたデータベース構造へと進化させることができます。
データの正規化の実践と注意点
データの正規化を実践する際には、理論だけでなく実際のデータベース設計や運用に関する知識が必要です。正規化の過程で、データの構造や関係性を深く理解することが、効果的なデータベース設計につながります。
正規化の手順
正規化の手順は以下のようになります:
データの分析:既存のデータ構造を詳細に分析し、依存関係や冗長性を特定します。
テーブルの分割:関連する情報を適切なテーブルに分割します。
キーの設定:各テーブルに適切な主キーを設定し、必要に応じて外部キーを定義します。
関係の定義:テーブル間の関係を明確にし、必要に応じてリレーションシップを設定します。
正規形の確認:各テーブルが目標とする正規形を満たしているか確認します。
例えば、「注文」テーブルから「顧客」情報を分離し、別テーブルとして管理することで、顧客情報の重複を避け、更新や管理を容易にすることができます。
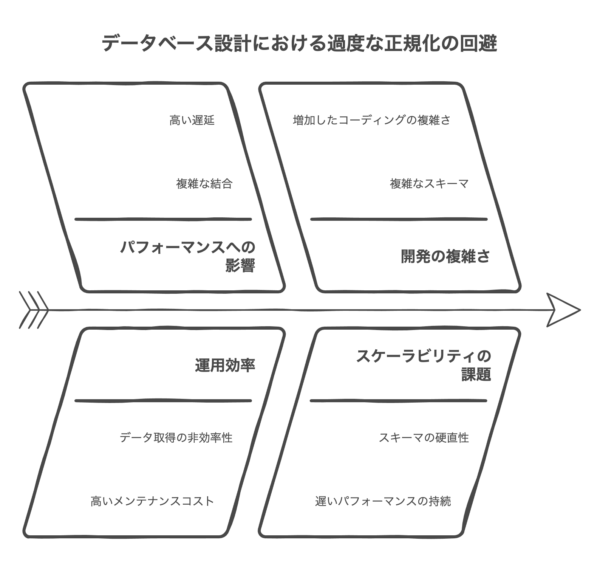
過度な正規化の注意点
正規化には多くの利点がありますが、過度な正規化にも注意が必要です。データベースの性能や使いやすさとのバランスを考慮することが重要です。
過度な正規化によって、以下のような問題が生じる可能性があります:
パフォーマンスの低下:テーブルが細かく分割されすぎると、データ取得時に多くの結合操作が必要となり、クエリの実行速度が低下する可能性があります。
複雑性の増加:テーブル数が増えることで、データベース構造が複雑になり、管理や理解が難しくなる場合があります。
開発効率の低下:細かく分割されたテーブルを扱うことで、アプリケーション開発の複雑さが増す可能性があります。
正規化は重要ですが、ビジネスニーズとのバランスを取ることも大切です。時には、意図的に非正規化を行うことで、パフォーマンスを向上させることもありますよ。
データの正規化がビジネスにもたらす影響
データの正規化は、単なる技術的な作業ではなく、ビジネス全体に大きな影響を与える重要な取り組みです。適切に実施されたデータの正規化は、様々な面でビジネスに利点をもたらします。
意思決定の質の向上
正規化されたデータベースは、より正確で一貫性のある情報を提供します。これにより、経営者や管理者は信頼性の高いデータに基づいて意思決定を行うことができます。
例えば、顧客データが正規化されていれば、顧客の購買傾向や嗜好を正確に分析することができ、的確なマーケティング戦略の立案につながります。
業務効率の改善
正規化されたデータベースは、データの更新や検索を効率的に行うことができます。これにより、日常的な業務プロセスが改善され、生産性が向上します。
例えば、在庫管理システムが適切に正規化されていれば、在庫状況の把握や発注プロセスが迅速化され、過剰在庫や欠品のリスクを低減することができます。
- データの整合性向上による信頼性の確保
- 効率的なデータ管理による運用コストの削減
- 柔軟なデータ分析による新たなビジネス機会の創出
- データセキュリティの強化によるリスク管理の向上
正規化されたデータベースは、ビジネスの様々な側面で競争優位性を生み出す重要な要素となります。
データの正規化は、ビジネスの基盤を強化する重要な投資です。短期的には手間がかかりますが、長期的には大きなリターンが期待できるでしょう!
データの正規化の未来と展望
テクノロジーの進化に伴い、データの正規化の概念や手法も進化を続けています。特に、ビッグデータやAIの時代において、データの正規化はますます重要性を増しています。
新たなデータ形式への対応
従来のリレーショナルデータベースだけでなく、NoSQLデータベースやグラフデータベースなど、新しいデータ形式に対応した正規化手法の開発が進んでいます。
例えば、IoTデバイスから生成される大量の非構造化データを効率的に管理するための正規化手法が研究されています。
自動化とAIの活用
機械学習やAIを活用した自動正規化ツールの開発が進んでいます。これらのツールは、大規模なデータセットを分析し、最適な正規化戦略を提案することができます。
将来的には、データベース設計の初期段階から運用段階まで、AIがデータの正規化を支援する時代が来るかもしれません。
このように、データの正規化は技術の進化とともに発展を続け、ますます重要性を増していくことが予想されます。ビジネスや研究の分野において、正規化の概念を理解し、適切に活用する能力は、今後さらに求められるスキルとなるでしょう。
よくある質問と回答
Answer データの正規化とは、データベースやデータセットを整理し、冗長性を排除して効率的に構造化するプロセスです。主な目的は、データの一貫性を保ち、更新や削除時の異常を防ぐことです。データベースでは、テーブルの分割や関係の定義を行い、機械学習では、データの前処理として特徴量のスケールを調整します。
Answer データの正規化の主な利点には以下があります: 1. データの一貫性と整合性の向上 2. 冗長性の削減によるストレージ効率の改善 3. データ更新や削除時の異常の防止 4. クエリのパフォーマンス向上 5. データ分析や機械学習モデルの精度向上
Answer データベースの正規化における主な正規形は以下の通りです: 1. 第一正規形(1NF):各列が原子値を持つ 2. 第二正規形(2NF):1NFを満たし、部分関数従属性がない 3. 第三正規形(3NF):2NFを満たし、推移的関数従属性がない 4. ボイス・コッド正規形(BCNF):より厳密な3NF 5. 第四正規形(4NF)と第五正規形(5NF):さらに高度な正規化
Answer 機械学習におけるデータの正規化は、以下の理由で重要です: 1. 特徴量のスケールを統一し、モデルの公平な学習を促進 2. 勾配降下法などの最適化アルゴリズムの収束速度を向上 3. 特定の特徴量が過度に影響を与えることを防止 4. モデルの解釈可能性を向上 5. 異なるスケールの特徴量間の比較を容易にする
Answer データの正規化の一般的な手法には以下があります: 1. Min-Max正規化:データを特定の範囲(通常0から1)にスケーリング 2. Z-スコア正規化:平均0、標準偏差1になるようにスケーリング 3. 小数スケーリング:小数点を移動させてスケーリング 4. ロバスト正規化:外れ値の影響を軽減する正規化 5. 対数変換:非線形の関係を線形に近づける変換
データの正規化は、効率的なデータ管理と分析の基盤となる重要な作業です。ビジネスの文脈や目的に応じて適切な正規化手法を選択することが、データ駆動型の意思決定を成功させる鍵となりますよ。
ビジネス環境では、一貫したデータ管理が競争力につながります。特に顧客との関係構築には、常に最新で正確な情報が求められるため、正規化は欠かせない手法です。